Artificiale, come l'intelligenza e gli allucinogeni
Qualche tempo fa ero nelle catacombe, a Parigi, tra migliaia di scheletri umani un tempo in carne ed ossa come me e voi altri: il posto ideale per scattare qualche foto evocativa. In effetti era la prima volta che fossi faccia-a-teschio con uno scheletro. Uno vero. Non che non ne avessi mai visti prima, è chiaro, ma mai dal vivo, mentre questo se ne stava lì, esanime, a lasciarsi fotografare, con il beneplacito della guida.
Sebbene fosse il primo head-to-head, come dicevo, un teschio l’avevo visto già da tempo, probabilmente in TV. In effetti è un’immagine che si impara presto a riconoscere. Basta che se ne veda uno, che la volta dopo lo si sappia identificare all’istante: “hei, quello è un teschio!”. Vale lo stesso per un cane; non è necessario che un bambino veda ogni razza di cane per imparare a riconoscerne uno: gli bastano un paio di esempi. E’ una capacità innata, la nostra, di generalizzare l’esperienza pregressa ed applicarla in situazioni nuove: che siano teschi, cani, amori passati o chissà cos’altro, è il nostro modo di conoscere il mondo. Una capacità che ci piacerebbe replicare artificialmente, così da raggiungere l’agognata meta che chiamiamo intelligenza artificiale.
Il così detto apprendimento automatico (o Machine Learning) è il campo di studi che unisce Computer science, neuroscienze e matematica applicata al fine di replicare questa nostra abilità su un computer. Pur non essendo un Data Scientist ed avendo appena qualche mese di esperienza in termini di Machine Learning, mi rendo conto che è un tema così gravido di conseguenze da meritare che chiunque sappia, sia pure a grandi linee, di cosa si stia parlando. Le applicazioni di Machine Learning e Deep Learning, che insieme costituiscono il fronte odierno dell’Intelligenza Artificiale (da ora AI), trovano largo sviluppo nella vita quotidiana: non solo automobili senza pilota, modelli finanziari, applicazioni biomediche e videogames, ma anche riconoscimento di volti, caratteri o suoni: vi siete mai chiesti come facciano Siri o Cortana a rispondervi a tono? Insomma, il tema è vastissimo e non sarò così incauto dal promettervi descrizioni puntuali di ogni sua sfumatura. Non ne sarei in grado! Al contrario proverò a sfiorare alcuni punti che ho ritenuto cruciali, promettendovi una sorpresa alla fine dell’articolo:
Qual è il campo di applicazione di queste tecnologie?
Perché la definiamo intelligenza artificiale e come si rapporta con l’intelligenza umana?
Come funziona il Machine Learning? Un esempio concreto.
Come impatta tutto ciò sulla nostra società e sui nostri sistemi etici e valoriali?
Un po' di biologia
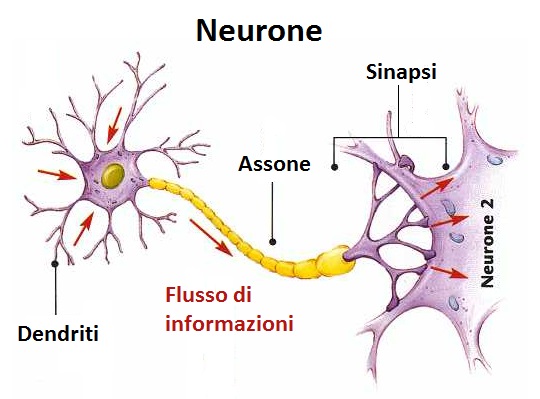
Come spesso accade, l’uomo trae ispirazione dai processi naturali per sviluppare le proprie tecnologie: come vedremo a breve, una conoscenza rudimentale sul funzionamento di un neurone potrà tornarci utile. Invito il lettore interessato ad approfondire il tema che qui sarà appena lambito.
Il neurone, che è l’unità cellulare del sistema nervoso, presenta da un lato una lunga protuberanza chiamata assone e dall'altro lato una serie di ramificazioni più corte chiamate dendriti. Ciascun neurone riceve segnali attraverso i suoi dendriti, li elabora nel corpo cellulare e poi, se l'input è superiore ad una certa soglia, genera un segnale d'uscita tramite l'assone.
Malgrado la semplicità di tale meccanismo, che pure è ben più intricato di come ho detto, il numero di neuroni ( circa 100 miliardi) e, soprattutto, il numero di interconnessioni tra di essi (cento mila miliardi) permette, per quanto ne sappiamo, l’emergenza di fenomeni complessi quali la coscienza o la memoria di cui siamo portatori. Dal punto di vista artificiale, ora, vedremo un meccanismo che ricalca il funzionamento di un singolo neurone: il Perceptron, che riceverà un certo numero di segnali dall'esterno, li elaborerà e produrrà un output.
Machine Learning & Deep Learning
Teniamo bene a mente il nostro scopo: avere un’idea di base di questi argomenti, senza entrare nel dettaglio. Per questo non posso che presentare un esempio che, tra tanti, risulta particolarmente immediato: il machine learning applicato all'assegnazione del credito. Immaginate un istituto di credito che utilizzi questi algoritmi per decidere se assegnare o meno del credito ad un potenziale cliente.
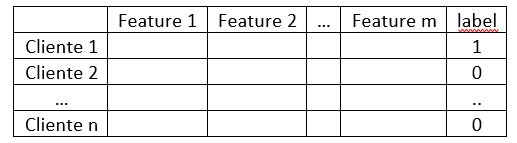
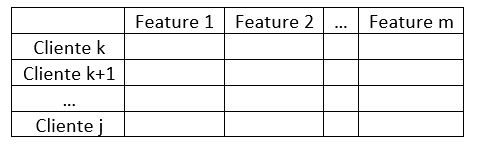
Il training set (letteralmente insieme di addestramento) è una tabella che contiene i dati su cui l’algoritmo si addestrerà. E' preferibile che sia di dimensioni tali da potersi dire afferente al mondo dei Big Data, al fine di irrobustire il modello, un dettaglio su cui non dirò null'altro. Nel nostro esempio potrebbe avere questa struttura:
dove ogni riga rappresenta un cliente che avrà delle caratteristiche (features) dalle quali se ne può desumere il merito creditizio (tanto per capirci: i Lannister hanno ottimo merito creditizio, giacché pagano sempre i propri debiti!). L’ultima colonna è quella dei label, che in questo problema sono di natura binaria:Si tratta dei dati di input, noti sin dall'inizio, su cui l’algoritmo si addestrerà. L’algoritmo di learning si eserciterà a trovare pattern e regolarità in questa tabella di dati, provando ad imparare, cliente per cliente, per quale combinazione delle diverse caratteristiche presenti, questi ripaga i suoi debiti (ovvero ha label 0) o meno (label 1). In altre parole, in questa fase l’algoritmo ricerca e impara la logica che ha spinto gli umani, un tempo incaricati di assegnare o negare il credito, a scegliere in un modo o nell'altro (0 o 1) a seconda delle informazioni disponibili: siamo noi uomini che abbiamo generato nel tempo ed aggregato questi dati su cui l’algoritmo sta ora imparando! Chi non ha molta dimestichezza con i numeri non si perda d'animo e salti le formule, leggendo però i commenti.
In forma compatta avremo un training set composto da coppie:A questo punto è necessario utilizzare l’algoritmo e ciò che ha imparato, su dati nuovi, che non ha mai visto, aggregati nella stessa forma dei precedenti, a meno dell’etichetta, che ora sarà assente:
E’ istruttivo lanciarsi in una piccola digressione, racchiusa nel Teorema “No Free Lunch” (non esiste pasto gratis): in generale non vi è un algoritmo di Learning migliore degli altri; a seconda dello scope, ve ne sono di vario tipo, ognuno con le proprie potenzialità ed i propri difetti . Col petto gonfio d’orgoglio, intanto, debbo dirvi che l’uomo sembra contraddire il teorema, viste le capacità di apprendimento generali che permettono di padroneggiare una moltitudine di problematiche differenti: dal riconoscimento dei volti, allo stesso interrogarsi su come realizzare l’AI. Prima di tornare al nostro problema di credit scoring come applicazione del Machine Learning, fornisco una prima classificazione degli algoritmi di learning in forma di spunto al lettore interessato:
Learning supervisionato, il caso qui presentato, in cui ciascuno degli esempi di addestramento è accompagnato da un’etichetta creata da un umano relativa a cosa deve essere appreso.
Learning non supervisionato: come sopra, ma senza che vi sia etichetta alcuna a guidare l’algoritmo;
Learning di rinforzo
Nel Learning supervisionato, inoltre, è possibile risolvere problemi di:
Classificazione, così come nel nostro caso.
Regressione
Torniamo al nostro problema, ricapitolandone i pilastri:
L’algoritmo si è addestrato sul training set, imparando la sua logica di classificazione in buoni (0) e cattivi (1) clienti.
L’algoritmo viene lanciato su dati che non ha mai visto e li deve classificare in buoni clienti o meno: in pratica generalizzare ciò che ha appreso in passato.
Trai vari algoritmi di classificazione binaria vi è il Perceptron, che pur non essendo il più accurato, risulta di immediata comprensione, sulla scorta dell’introduzione biologica di cui sopra. Si parte dal concetto di “funzione ipotesi”:
Così come nella biologia del neurone ogni input si manifesta con una propria intensità, anche nel modello artificiale del Perceptron vi sarà un vettore di pesi per gli input.
E’ questo vettore di pesi, da assegnare alle varie features, che l’algoritmo di learning va a calcolare. Il come, tipicamente, può risultare complicato e varia in base al tipo di learning scelto. Per dare un’idea semplice, però, poniamo il seguente caso. Se diciamo che la funzione ipotesi ha la forma di una logistica:
Il tutto, ora, sta nel trovare i pesi w migliori, che minimizzino l’errore di generalizzazione (una questione decisiva, su cui non entreremo nel merito). Immaginando il Perceptron come unità neurale artificiale (come il neurone per il sistema nervoso), una rete neurale può essere immaginata come un insieme di questi neuroni sintetici interconnessi tra loro in cui l’output dell’uno rappresenta l’input degli altri. Su questa, ad esempio, si può dare forma ad un sistema di apprendimento profondo (o deep learning). Altri esempi immediati di classificazione mediante machine learning supervisionato sono:
il riconoscimento di immagini (stessa logica: il training set avrà ora matrici di pixel anziché clienti e i label, anziché 0 ed 1 potrebbero essere cane, gatto, uomo, ad esempio, o ciò che si vuole riconoscere!);
i sistemi per finalità di sicurezza o biomediche (riconoscere un’insufficienza cardiaca da una immagine di RM come un cardiologo in carne ed ossa);
il riconoscimento dei suoni (Shazam, Siri, Cortana, etc)
lo studio dei dati astronomici, di quelli derivanti dalle collisioni di particelle, dei dati sociali, economici, etc.
Insomma, avrei potuto tralasciare questa parte di carattere (un po’ più) quantitativo, dicendo solo che l’obiettivo è approssimare bene i dati sul training set ma allo stesso tempo generalizzare bene su un set di dati nuovo, ma ora, sia pure in maniera generale ed imprecisa, ognuno di voi avrà un’idea della posta in gioco. Possiamo avviarci verso la conclusione.
L’impatto sulla società
Nell'immaginario collettivo l’avvento della AI è foriero di scenari apocalittici, in cui macchine super intelligenti si fanno in 4 per sottomettere il genere umano ai loro scopi. Più verosimilmente, come racconta Jesse Emspak per ScientificAmerican, il quadro sarà un altro:
Gli algoritmi di apprendimento automatico che già consentono ai programmi di intelligenza artificiale di raccomandarci un film o riconoscere il viso di un amico in una foto saranno probabilmente gli stessi che un giorno ci negheranno un prestito, faranno arrivare la polizia nel vostro quartiere o diranno al vostro medico che avete bisogno di una dieta.
Una parte non trascurabile del Deep Learning che assolve a tali scopi è definibile come “black box”, una scatola nera nella quale infilare input che verranno elaborati in maniera quasi del tutto oscura per produrre, alla fine, un output che noi umani andremo ad utilizzare. In un certo senso una scatola nera che consente di risolvere un problema, ma non di capirlo. Le circostanze misteriose che determinano quest’output non sono poi così rassicuranti: finché si parla di AlphaGo che, attraverso complessi algoritmi di Deep Learning, batte ripetutamente il campione mondiale del complesso gioco di ruolo cinese, c’è poco da preoccuparsi; ma in circostanze più delicate come l’assegnazione di un mutuo, un’auto senza pilota, la pubblica sicurezza o la salute, non sapere come queste scatolette tiran fuori le risposte potrebbe essere un problema. A voler fare l’avvocato del diavolo, potrei dire che, in effetti, non sappiamo bene come noi umani tiriamo fuori le stesse risposte, eppure non ci preoccupiamo troppo che sia un uomo a guidare un Taxi, ad assegnarci del credito, a operarci chirurgicamente. Non dimentichiamo, infatti, che i processi di scoperta del funzionamento della mente umana e di creazione di queste tecnologie viaggiano in parallelo, anche se sarebbe assai utile capire prima come noi umani impariamo dall'esperienza e solo dopo replicarne il prodigio su un computer.
Un altro problema che affligge queste tecnologie è la qualità dei dati. Come ho spiegato, per funzionare bene, gli algoritmi di ML hanno bisogno di grandi moli di dati su cui imparare (Big Data), ma una volta ottenuti, bisognerebbe preoccuparsi della loro qualità con considerazioni di dominio. Un esempio?
Un gruppo di ricercatori recentemente ha pubblicato uno studio affermando che un algoritmo è in grado di dedurre se una persona è un pregiudicato valutandone i tratti del viso. Anche se potrebbe sembrare che lo studio convalidi alcuni aspetti della fisiognomica, la secolare pseudoscienza figlia di Lombroso, l’autore riconosce che sarebbe "folle" usare quella tecnologia per scegliere qualcuno da un elenco di polizia, e dice che non c'è alcun progetto per qualsivoglia applicazione di polizia. Dopo aver guardato il 90% delle immagini (training set), l'AI è stata in grado di identificare correttamente nel restante 10% di foto quelle dei criminali condannati (test set). I ricercatori hanno continuato a testare l'algoritmo usando un diverso insieme di foto che l'AI non aveva visto in precedenza, scoprendo che poteva individuare correttamente un condannato più spesso di quanto sbagliasse. Alcuni scienziati dicono che le scoperte dello studio appena citato possono semplicemente rafforzare pregiudizi esistenti. La criminalità dei soggetti è stata determinata da un sistema giudiziario locale gestito da esseri umani che prendono (magari inconsciamente) decisioni di parte. Il problema centrale di questo algoritmo è che si basa su questo sistema come verità di riferimento per etichettare i criminali, e quindi conclude che l'apprendimento automatico che ne risulta non è distorto dalla valutazione umana. Questo algoritmo può semplicemente riflettere la polarizzazione degli esseri umani in un particolare sistema giudiziario, e potrebbe fare la stessa cosa in qualsiasi altro paese.
Il tema è chiaro: se l’algoritmo si addestra a classificare tumori, debitori o delinquenti sulla scorta del nostro modo di farlo, imparerà anche i nostri pregiudizi, le nostre debolezze, i nostri errori. Anche su questo si dovrebbe riflettere attentamente.
Algoritmi ed LSD
Vi avevo promesso una sorpresa.
Ricordate l’immagine da cui tutto è partito? Il teschio parigino? Ebbene, niente è per caso in questo articolo. Google possiede un riconoscitore di immagini che sfrutta algoritmi simili (ma più complessi!) a quelli descritti sopra. Lo scopo è sempre il medesimo: allenarsi su un training set di tantissime immagini (in questo caso, mentre prima eran clienti) e, generalizzando, classificare delle immagini nuove.
Un algoritmo di learning che classifichi foto di cani, ad esempio, paragona l’immagine sottopostagli con tutte quelle che ha visto in passato in cerca di un’analogia: se ne trova una ci dice che, sì, quello è un cane. Ma cosa accade se gli mostriamo una foto del tutto priva di cani, dicendogli, in malafede, che lì un cane c’è eccome? Ebbene, l’algoritmo si metterà alla ricerca di quella combinazione di pixel che più assomiglia ad un cane (o ai cani che ha visto nel training set!), anche se un cane nella foto, in effetti, non c’è. E se noi gli diciamo che c’è, lui, da probo servo, ci crede! Ora, cosa accadrebbe se modificassimo il software in modo che quando esso trova un qualcosa che gli ricorda un cane (anche se non c’è!), ha facoltà di modificare quella parte di immagine per renderla ancora più simile ad un cane? Ebbene, guardate voi stessi il risultato di un algoritmo che non classifica solo cani, ma scimmie, uccelli, volti umani e molto altro.
Iterando il processo l’algoritmo amplifica la modifica iniziale, creando volti, prima distorti e poi sempre più definiti, dal nulla più assoluto, in una rappresentazione onirica, degna dei migliori allucinogeni comperati ai rave pary. Funziona anche se gli date in pasto del rumore bianco (distribuzione casuale di colori, che è la mancanza di senso per antonomasia): l’algoritmo, step by step, vi troverà/costruirà dei volti, degli animali, delle mostruosità, inquietanti ed al contempo spettacolari, come quelle che vedete. qui
Nel salutarvi, vi propongo un’immagine del sottoscritto, in cui un palazzo diventa misteriosamente una "volpe fattona", o qualcosa del genere.
Insomma, magari un giorno prenderanno il sopravvento, ma per ora le macchine su cui implementiamo queste tecnologie sono goffe, pregiudizievoli e un poco allucinate, così come noi che le abbiamo generate.
Riferimenti
The Credit Scoring, Theory and practice for retail credit risk management and decision automation – Raymond Anderson
LeScienze , Agosto 2016
In aggiunta ai numerosi link di cui l'articolo è puntellato.




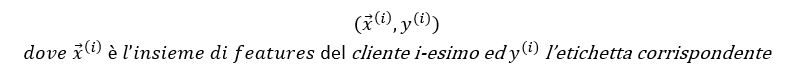
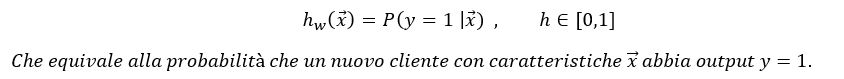

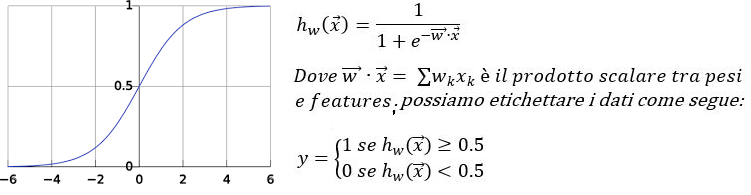



Commenti